
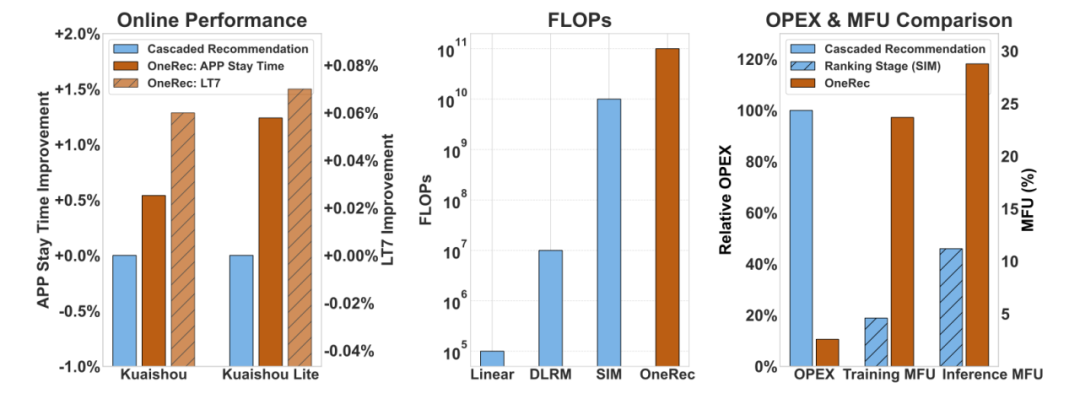
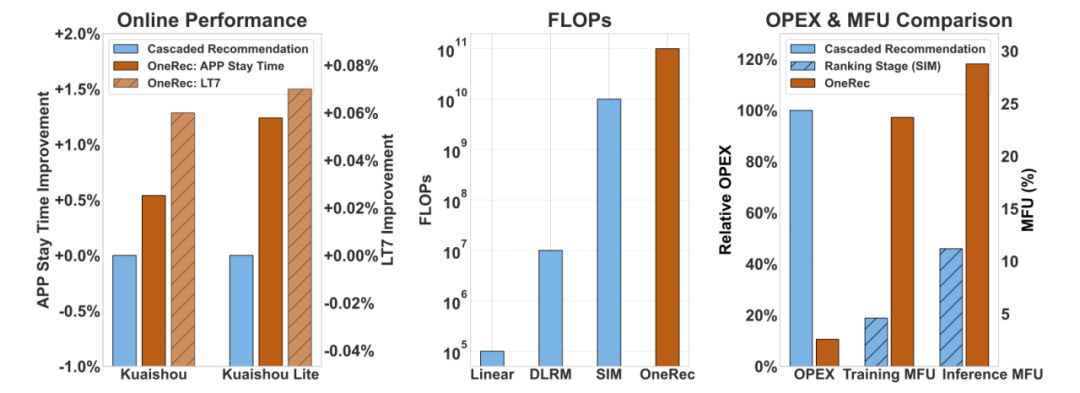
 当今不可避免的推荐系统正在以新的AI动力进行管理。当AI领域发起了由大语言模型(LLM)领导的生成革命时,他们开始在各个领域重新创建传统的技术堆栈,其良好的完成技巧,对数据的大量了解以及尚未潜在的内容产生。作为一台主要的互联网交通机器,推荐系统面临着诸如破坏级联体系结构目标的计算强度和破坏的问题,并逐渐阻止其创新的开发。从碎片组装到集成集成的范式转移是推荐系统生存的唯一途径,并且使用NG LLM技术来重建架构以取得改进的结果和降低的成本是关键。最近,Kuaishou技术团队提供了答案,最新建议的“ Onerec”正在建立推荐的整个链接首次具有端到端生成体系结构的系统。在冲击和成本之间看似为零的游戏中,ONEC使“既想要和想要”成为可能:从角度来看:推荐模型的有效计算量增加了10倍,并且在推荐情况下再次出现了“不在当地环境中”的刺激研究技术;从成本的角度来看:通过更改建筑水平,MFU培训/识别模型(电源计算使用的识别模型)提高到23.7%/28.8%,而KoMunications的急剧减少和高架储存使运营成本(OPEX)仅占传统解决方案的10.6%。目前,该系统已为所有用户提供了Kuaishou App/Kuaishou Speed Edition双端的服务,该系统约有25%的QP(每秒请求数),使该应用程序中的停留时间增加了0.54%/1.24%。 7天用户生命周期(LT7)的主要指标是显着的增加,提供第一个可以使用级别的建议系统来完成的解决方案,该建议系统从传统管道转移到端到端的生成架构。下图(左)显示了与Kuaishou/Kuaishou Speed Edition中Onerec和级联推荐架构的性能的在线比较。图(中间)显示了OneRec和线性,DLRM和SIM的拖鞋的比较。该图(右)显示了Onerec和级联建议体系结构的fealopex bing,以及SIM的MFU比较,SIM是该链接上精细模型调度的最计算复杂性,背后是相同的计算和计算效率影响的影响。 Onerec在建筑设计和培训框架方面具有一系列创新的突破。完成指向技术报告的链接:https://arxiv.org/abs/2506.13695突破传统级联体系结构的束缚。推荐算法,fROS今天,分解机器对深神经网络的早期因素无法摆脱多阶段级联建筑的障碍。这种碎片设计面临以下三个主要瓶颈:首先,计算能力差已成为致命的伤害。作为一个例子,在推荐系统中的精细测定模型(SIM)的最高计算复杂性也是在GPU的旗舰上训练/推荐的。理论MFU(模型Flops利用率)仅为4.6%/11.2%,小于大型H100语言模型的40%-50%;其次,该功能目的之间的冲突变得越来越严重,平台需要能够优化路径 - 用户,创建者和生态系统的目标。这些目标在不同的阶段相互阻止,从而导致系统的一致性和效率持续恶化;更严重的是,我的区别n技术的产生正在扩大,现有的体系结构很难在AI领域(例如法律规模和研究强化)中获得最新成功,并且很难使用最新计算硬件的全部容量,这使得推荐系统的开发和基本AI技术的开发逐渐逐渐恶化。面对这些挑战,Kuaishou Teching团队建议ONEREC推荐的端到端生成系统。这主要在于使用编码器来压缩对用户一生的使用以实现兴趣的依从性。同时,基于MOE的架构的解码器实现了超大规模参数的扩展,以确保端到端准确地生成简短的视频建议;该模型结合了学习强化和优化的最终培训/优化的自定义框架,实现了影响和效率的获胜效果。下图是OneRec系统的一般任务。幸运的是,这种新的系统对以下方面有重大影响:它可以使用更大的模型来获得比在线系统低的成本更好的推荐结果;在一定范围内,发现了建议的方案的法律;难以影响和优化过去结果的RL技术在该体系结构中具有很高的潜力。目前,该系统靠近LLM社区从培训到建筑和MFU级别的传输,并且在该系统中可以正确实施许多LLM社区技术。 OneRec基本模型分析Onerec采用了编码器编码器的体系结构,转换为发电顺序工作的推荐问题,并使用NTP(下一个标记预测)在Thetrawing期间的优化优化丢失。下图显示了编码器架构的完整组件。语义单词细分器面孔Kuaishou平台上的公路数百万视频内容,如何使模型“理解”每个主要挑战的每个视频。 Onerec开创了与多模式单词分割方案的合作:多模式融合:同时处理视频中的多维信息,例如标题,标签,标签,语音语音,图像识别等。结合信号集成:不仅侧重于内容特征,还包括建模用户行为信息。分层语义编码:使用RQ-KMEANS技术,每个视频都将转换为3层厚到薄的语义ID。训练阶段的编码器架构Onerec通过编码器decoder架构进行了Sucknod令牌预测,从而实现了目标项目的预测。编解码器阶段此体系结构的功能如下:用户建模的多尺寸级别:编码阶段考虑了相同的静态用户,短期行为的序列,Effec一生中的观察序列和行为序列。专家混合解码器:解码阶段采用了一种逐点生成的方法来通过专家的体系结构(MOE)来提高模型的容量和效率。推荐系统的扩展法参数量表实验是ONEC研究的另一个亮点,该研究试图回答一个关键问题:建议系统是否还遵循大型语言模型的Scalinga领域的可靠合法化?实验结果清楚地表明,随着参数模型体积从0.015b增加到2.633b,训练的损失显示出显着的下降速度。有关详细信息,请参见改变下图中损失的曲线。此外,技术报告还介绍了功能,包括功能,代码本和推断缩放功能,该功能极大地利用计算强度来提高建议的准确性。预先经验的冰鞋的研究研究研究(RL)模型LS即使可以通过接下来的令牌预测进行裸露的物品的空间分布,这些暴露的项目也来自过去的传统推荐系统,这使该模型不会通过执行上限NG传统推荐系统而破坏。为了解决这一挑战,Onerec使用强化研究提出了一种基于奖励机制的作弊偏好的方式,以增强模型的影响。通过奖励反馈机制,该模型可以找到用户偏好的更好信息。直到今天,Onerec建立了一个全面的奖励系统:偏好的奖励:用于使用户偏好保持一致。格式奖励:确保所有形成的令牌都采用有效格式。工业奖励:满足不同业务情况的需求。下图是奖励系统的一般框架。应该奖励什么样的视频? Onerec建议采用偏好奖励模型,可以在“ Pers基于用户特征的各种目标比例值的征收融合。“ p-评分”标记被用作通过改进版本的GRPO ECPO(早期剪切GRPO)进行加强和优化的奖励。如下图所示,ECPO进行了更严格的策略性置换(0)示例的策略性(A 0)与GRPO相比,请逐步训练,以使Same Sumplize与Same Supplige相比。 Onerec进行了一项实验,研究了Kuaishou/Kuaishou Speed Edition方案中的增强性,在线结果表明,使用时间大大改善了视频,而下表则表明了Onerec的“ P-Score”的奖励。但是分类的传统推荐模型tion has long-term deepest trapped in" single-digit that accumulates in business, such as the number of Kuaishou Fine-scheduling model operators is as high as 15,000+, and the complex structure makes it impossible to perform deep optimization such as LLM; a ceiling of performance, and the rate of use of GPU computing strengthis less than 10% in a long period of time. Onerec's generative architecture has brought a collapse of change: by using LLM的体系结构像编码器一样简化了组件,迫使92%至1,200的主要运营商数量,并通过更大的模型量表来改善计算密度;通过重建推荐的链接,释放压力延迟,MFU培训/识别率允许23.7%和28.6%的系统,以分别达到3-5-5。与第一个AI的基本模型相媲美的计算效率。Al Team还对训练和地下水平的OnEREC功能进行了深刻的自定义优化。 ONEREC在训练阶段反对训练,通过以下核心 - 压迫实现加速:压缩压缩:对于同一请求下的许多曝光样本(由于同时发送6个视频,平均5个接触),这些示例共享用户和上下文特征。 kuaishou与请求ID结合在一起,以避免在上下文上下文中重复出现的FFN计算。同时,使用可变的长闪光注意力,这有效地避免了重复访问KV内存访问,并进一步提高了注意力计算的密度。加速优化:为了应对单个样本超过1000万相参数的训练挑战,Kuaishou技术团队已经成为Skai系统,意识到整个练习过程已经完成了GPU的整个练习过程,以防止中断GPU/CPU离子;单个GPU内存管理(UGMMU)大大减少了内核的数量。加权LFU智能缓存算法用于利用数据局部性的整个时间,参数和模型计算的传输是通过嵌入预摘要管道来覆盖的,有效地隐藏了递送延迟,并且嵌入训练效率的整体提高得到了极大的提高。此外,还有一些基本技术来优化,例如出色的训练,混合混合精度和汇编。在理解阶段的优化中,Onerec采用了较大的光束尺寸(通常为512),以改善差异不同,并覆盖了开发的建议。面对如此大规模的需求,Kuaishou技术团队已从多种尺寸(例如多重计算,运算符优化和系统调度)进行了深入的优化:计算多功能优化:OneRec使用多种方法计算E是用户请求e e eang ncoder功能完全平行于所有光束,因此仅需要计算一次编码器一次,避免重复计算;其次,在解码器生成期间,十字架注意力的关键/值分布在所有光束上,这大大降低了记忆的使用和计算强度的消耗;同时,解码器使用I -Cache内部的KV缓存机理是历史步骤的关键/值,进一步降低了双重计算。操作员级优化:Onerec的构想阶段完全采用了FLATE16混合动力车的准确性计算,从而大大提高了计算速度并减少了视频记忆的使用。同时,对MOE,注意力和BeamSearch等主要运营商进行了内核和手动优化的深层融合,这有效地减少了GPU内核的启动和内存访问的数量LY提高了操作员和一般吞吐量功能的计算效率。此外,还有独家选项,例如System -Scheduling。通过优化的上层系统技术,ONEC在训练和识别中的MFU分别达到23.7%和28.8%,这是显着改善的,而传统推荐模型的4.6%和11.2%。运营成本降低到传统解决方案的10.6%,可节省约90%的成本。 ONEC在线实验结果对Kuaishou主站点/双端应用程序速度的简短视频建议的关键情况进行了严格的实验。通过测试AB 5%的流量一周,纯生成模型(ONEREC)取得了与基于RL对齐的原始复杂推荐系统相同的效果,而叠加奖励模型选择策略(具有RM选择的ONEREC)在增加KU居住时间的成功取得了重大成功Aishou系统,改进Kuaishou系统。停留时间或0.01%LT7具有统计学意义。更值得关注的是,Modelo已经获得了对所有交互式指标(例如偏好,注意力和评论)的积极回报(如下表所示),证明它可以防止多任务系统的“ Seeesaw效应”以实现全局优化。在简短的视频建议的主要方案中,该系统已促进给所有用户,并执行约25%的请求(QPS)。除了简短视频推荐的消费场景外,Onerec在Kuaishou的本地生活服务方案中还表现出色:AB比较实验表明,该计划鼓励GMV增长21.01%,订单量增长21.01%,用户数量增加了17.89%,并增加了17.89%的用户的数量增长了17.89%的使用率。流泪了增加23.02%。目前,这一业务已达到100%的全部交通转移。值得注意的是,与实验阶段相比,整个在线学位后的指标的增长率得到了进一步扩展,这完全证实了一般的ONEC在各种业务情况下的能力。结论生成的AI充分,会产生重大的技术变化,降低成本和提高各个领域的效率。随着Kuaishou Onerec的新范式的出现,推荐系统将加速“端到端的生成觉醒”时刻。 Onerec不仅表明了建议系统和LLM技术堆栈的深入整合,而且基本互联网基础架构的技术DNA是对技术DNA的重新组成的。一方面,系统NG建议的技术范式通过创新的端到端生成架构进行了重新组织。另一方面,通过强烈的Engin在撞击和效率的双重大小上,实现了综合的超越。当然,新系统中仍然有许多需要改进的地方。 Kuaishou技术团队教授了三个方向要破坏:推理能力:扩大步骤步骤的扩展功能并不明显,这表明Onerec没有强大的推理能力;多模式桥:在用户行为模式和LLM/VLM之间开发融合的本地体系结构,利用VLM中的跨模式对准技术,实现了对用户行为序列,视频内容和语义空间的统一研究,并成为整个模型的本地模型;完整的Systema奖励:当前的设计非常重要。在Onerec的端到端体系结构下,奖励系统会影响在线结果和离线培训。 Kuaishou希望使用这种能力来指导模型更好地了解用户的偏好和业务需求,并提供更好的建议EXP精华。可以预测,Onerec无疑会为未来增添更多的AI功能,这将变得更强大,从而为包括Kuaishou在内的更广泛的推荐申请情况释放了更多的价值。
当今不可避免的推荐系统正在以新的AI动力进行管理。当AI领域发起了由大语言模型(LLM)领导的生成革命时,他们开始在各个领域重新创建传统的技术堆栈,其良好的完成技巧,对数据的大量了解以及尚未潜在的内容产生。作为一台主要的互联网交通机器,推荐系统面临着诸如破坏级联体系结构目标的计算强度和破坏的问题,并逐渐阻止其创新的开发。从碎片组装到集成集成的范式转移是推荐系统生存的唯一途径,并且使用NG LLM技术来重建架构以取得改进的结果和降低的成本是关键。最近,Kuaishou技术团队提供了答案,最新建议的“ Onerec”正在建立推荐的整个链接首次具有端到端生成体系结构的系统。在冲击和成本之间看似为零的游戏中,ONEC使“既想要和想要”成为可能:从角度来看:推荐模型的有效计算量增加了10倍,并且在推荐情况下再次出现了“不在当地环境中”的刺激研究技术;从成本的角度来看:通过更改建筑水平,MFU培训/识别模型(电源计算使用的识别模型)提高到23.7%/28.8%,而KoMunications的急剧减少和高架储存使运营成本(OPEX)仅占传统解决方案的10.6%。目前,该系统已为所有用户提供了Kuaishou App/Kuaishou Speed Edition双端的服务,该系统约有25%的QP(每秒请求数),使该应用程序中的停留时间增加了0.54%/1.24%。 7天用户生命周期(LT7)的主要指标是显着的增加,提供第一个可以使用级别的建议系统来完成的解决方案,该建议系统从传统管道转移到端到端的生成架构。下图(左)显示了与Kuaishou/Kuaishou Speed Edition中Onerec和级联推荐架构的性能的在线比较。图(中间)显示了OneRec和线性,DLRM和SIM的拖鞋的比较。该图(右)显示了Onerec和级联建议体系结构的fealopex bing,以及SIM的MFU比较,SIM是该链接上精细模型调度的最计算复杂性,背后是相同的计算和计算效率影响的影响。 Onerec在建筑设计和培训框架方面具有一系列创新的突破。完成指向技术报告的链接:https://arxiv.org/abs/2506.13695突破传统级联体系结构的束缚。推荐算法,fROS今天,分解机器对深神经网络的早期因素无法摆脱多阶段级联建筑的障碍。这种碎片设计面临以下三个主要瓶颈:首先,计算能力差已成为致命的伤害。作为一个例子,在推荐系统中的精细测定模型(SIM)的最高计算复杂性也是在GPU的旗舰上训练/推荐的。理论MFU(模型Flops利用率)仅为4.6%/11.2%,小于大型H100语言模型的40%-50%;其次,该功能目的之间的冲突变得越来越严重,平台需要能够优化路径 - 用户,创建者和生态系统的目标。这些目标在不同的阶段相互阻止,从而导致系统的一致性和效率持续恶化;更严重的是,我的区别n技术的产生正在扩大,现有的体系结构很难在AI领域(例如法律规模和研究强化)中获得最新成功,并且很难使用最新计算硬件的全部容量,这使得推荐系统的开发和基本AI技术的开发逐渐逐渐恶化。面对这些挑战,Kuaishou Teching团队建议ONEREC推荐的端到端生成系统。这主要在于使用编码器来压缩对用户一生的使用以实现兴趣的依从性。同时,基于MOE的架构的解码器实现了超大规模参数的扩展,以确保端到端准确地生成简短的视频建议;该模型结合了学习强化和优化的最终培训/优化的自定义框架,实现了影响和效率的获胜效果。下图是OneRec系统的一般任务。幸运的是,这种新的系统对以下方面有重大影响:它可以使用更大的模型来获得比在线系统低的成本更好的推荐结果;在一定范围内,发现了建议的方案的法律;难以影响和优化过去结果的RL技术在该体系结构中具有很高的潜力。目前,该系统靠近LLM社区从培训到建筑和MFU级别的传输,并且在该系统中可以正确实施许多LLM社区技术。 OneRec基本模型分析Onerec采用了编码器编码器的体系结构,转换为发电顺序工作的推荐问题,并使用NTP(下一个标记预测)在Thetrawing期间的优化优化丢失。下图显示了编码器架构的完整组件。语义单词细分器面孔Kuaishou平台上的公路数百万视频内容,如何使模型“理解”每个主要挑战的每个视频。 Onerec开创了与多模式单词分割方案的合作:多模式融合:同时处理视频中的多维信息,例如标题,标签,标签,语音语音,图像识别等。结合信号集成:不仅侧重于内容特征,还包括建模用户行为信息。分层语义编码:使用RQ-KMEANS技术,每个视频都将转换为3层厚到薄的语义ID。训练阶段的编码器架构Onerec通过编码器decoder架构进行了Sucknod令牌预测,从而实现了目标项目的预测。编解码器阶段此体系结构的功能如下:用户建模的多尺寸级别:编码阶段考虑了相同的静态用户,短期行为的序列,Effec一生中的观察序列和行为序列。专家混合解码器:解码阶段采用了一种逐点生成的方法来通过专家的体系结构(MOE)来提高模型的容量和效率。推荐系统的扩展法参数量表实验是ONEC研究的另一个亮点,该研究试图回答一个关键问题:建议系统是否还遵循大型语言模型的Scalinga领域的可靠合法化?实验结果清楚地表明,随着参数模型体积从0.015b增加到2.633b,训练的损失显示出显着的下降速度。有关详细信息,请参见改变下图中损失的曲线。此外,技术报告还介绍了功能,包括功能,代码本和推断缩放功能,该功能极大地利用计算强度来提高建议的准确性。预先经验的冰鞋的研究研究研究(RL)模型LS即使可以通过接下来的令牌预测进行裸露的物品的空间分布,这些暴露的项目也来自过去的传统推荐系统,这使该模型不会通过执行上限NG传统推荐系统而破坏。为了解决这一挑战,Onerec使用强化研究提出了一种基于奖励机制的作弊偏好的方式,以增强模型的影响。通过奖励反馈机制,该模型可以找到用户偏好的更好信息。直到今天,Onerec建立了一个全面的奖励系统:偏好的奖励:用于使用户偏好保持一致。格式奖励:确保所有形成的令牌都采用有效格式。工业奖励:满足不同业务情况的需求。下图是奖励系统的一般框架。应该奖励什么样的视频? Onerec建议采用偏好奖励模型,可以在“ Pers基于用户特征的各种目标比例值的征收融合。“ p-评分”标记被用作通过改进版本的GRPO ECPO(早期剪切GRPO)进行加强和优化的奖励。如下图所示,ECPO进行了更严格的策略性置换(0)示例的策略性(A 0)与GRPO相比,请逐步训练,以使Same Sumplize与Same Supplige相比。 Onerec进行了一项实验,研究了Kuaishou/Kuaishou Speed Edition方案中的增强性,在线结果表明,使用时间大大改善了视频,而下表则表明了Onerec的“ P-Score”的奖励。但是分类的传统推荐模型tion has long-term deepest trapped in" single-digit that accumulates in business, such as the number of Kuaishou Fine-scheduling model operators is as high as 15,000+, and the complex structure makes it impossible to perform deep optimization such as LLM; a ceiling of performance, and the rate of use of GPU computing strengthis less than 10% in a long period of time. Onerec's generative architecture has brought a collapse of change: by using LLM的体系结构像编码器一样简化了组件,迫使92%至1,200的主要运营商数量,并通过更大的模型量表来改善计算密度;通过重建推荐的链接,释放压力延迟,MFU培训/识别率允许23.7%和28.6%的系统,以分别达到3-5-5。与第一个AI的基本模型相媲美的计算效率。Al Team还对训练和地下水平的OnEREC功能进行了深刻的自定义优化。 ONEREC在训练阶段反对训练,通过以下核心 - 压迫实现加速:压缩压缩:对于同一请求下的许多曝光样本(由于同时发送6个视频,平均5个接触),这些示例共享用户和上下文特征。 kuaishou与请求ID结合在一起,以避免在上下文上下文中重复出现的FFN计算。同时,使用可变的长闪光注意力,这有效地避免了重复访问KV内存访问,并进一步提高了注意力计算的密度。加速优化:为了应对单个样本超过1000万相参数的训练挑战,Kuaishou技术团队已经成为Skai系统,意识到整个练习过程已经完成了GPU的整个练习过程,以防止中断GPU/CPU离子;单个GPU内存管理(UGMMU)大大减少了内核的数量。加权LFU智能缓存算法用于利用数据局部性的整个时间,参数和模型计算的传输是通过嵌入预摘要管道来覆盖的,有效地隐藏了递送延迟,并且嵌入训练效率的整体提高得到了极大的提高。此外,还有一些基本技术来优化,例如出色的训练,混合混合精度和汇编。在理解阶段的优化中,Onerec采用了较大的光束尺寸(通常为512),以改善差异不同,并覆盖了开发的建议。面对如此大规模的需求,Kuaishou技术团队已从多种尺寸(例如多重计算,运算符优化和系统调度)进行了深入的优化:计算多功能优化:OneRec使用多种方法计算E是用户请求e e eang ncoder功能完全平行于所有光束,因此仅需要计算一次编码器一次,避免重复计算;其次,在解码器生成期间,十字架注意力的关键/值分布在所有光束上,这大大降低了记忆的使用和计算强度的消耗;同时,解码器使用I -Cache内部的KV缓存机理是历史步骤的关键/值,进一步降低了双重计算。操作员级优化:Onerec的构想阶段完全采用了FLATE16混合动力车的准确性计算,从而大大提高了计算速度并减少了视频记忆的使用。同时,对MOE,注意力和BeamSearch等主要运营商进行了内核和手动优化的深层融合,这有效地减少了GPU内核的启动和内存访问的数量LY提高了操作员和一般吞吐量功能的计算效率。此外,还有独家选项,例如System -Scheduling。通过优化的上层系统技术,ONEC在训练和识别中的MFU分别达到23.7%和28.8%,这是显着改善的,而传统推荐模型的4.6%和11.2%。运营成本降低到传统解决方案的10.6%,可节省约90%的成本。 ONEC在线实验结果对Kuaishou主站点/双端应用程序速度的简短视频建议的关键情况进行了严格的实验。通过测试AB 5%的流量一周,纯生成模型(ONEREC)取得了与基于RL对齐的原始复杂推荐系统相同的效果,而叠加奖励模型选择策略(具有RM选择的ONEREC)在增加KU居住时间的成功取得了重大成功Aishou系统,改进Kuaishou系统。停留时间或0.01%LT7具有统计学意义。更值得关注的是,Modelo已经获得了对所有交互式指标(例如偏好,注意力和评论)的积极回报(如下表所示),证明它可以防止多任务系统的“ Seeesaw效应”以实现全局优化。在简短的视频建议的主要方案中,该系统已促进给所有用户,并执行约25%的请求(QPS)。除了简短视频推荐的消费场景外,Onerec在Kuaishou的本地生活服务方案中还表现出色:AB比较实验表明,该计划鼓励GMV增长21.01%,订单量增长21.01%,用户数量增加了17.89%,并增加了17.89%的用户的数量增长了17.89%的使用率。流泪了增加23.02%。目前,这一业务已达到100%的全部交通转移。值得注意的是,与实验阶段相比,整个在线学位后的指标的增长率得到了进一步扩展,这完全证实了一般的ONEC在各种业务情况下的能力。结论生成的AI充分,会产生重大的技术变化,降低成本和提高各个领域的效率。随着Kuaishou Onerec的新范式的出现,推荐系统将加速“端到端的生成觉醒”时刻。 Onerec不仅表明了建议系统和LLM技术堆栈的深入整合,而且基本互联网基础架构的技术DNA是对技术DNA的重新组成的。一方面,系统NG建议的技术范式通过创新的端到端生成架构进行了重新组织。另一方面,通过强烈的Engin在撞击和效率的双重大小上,实现了综合的超越。当然,新系统中仍然有许多需要改进的地方。 Kuaishou技术团队教授了三个方向要破坏:推理能力:扩大步骤步骤的扩展功能并不明显,这表明Onerec没有强大的推理能力;多模式桥:在用户行为模式和LLM/VLM之间开发融合的本地体系结构,利用VLM中的跨模式对准技术,实现了对用户行为序列,视频内容和语义空间的统一研究,并成为整个模型的本地模型;完整的Systema奖励:当前的设计非常重要。在Onerec的端到端体系结构下,奖励系统会影响在线结果和离线培训。 Kuaishou希望使用这种能力来指导模型更好地了解用户的偏好和业务需求,并提供更好的建议EXP精华。可以预测,Onerec无疑会为未来增添更多的AI功能,这将变得更强大,从而为包括Kuaishou在内的更广泛的推荐申请情况释放了更多的价值。

